Código
library(tidyverse)
library(scales)
# Configuración de tema para gráficos
theme_set(theme_minimal(base_size = 11))En hidrología, es frecuente necesitar determinar a qué percentil corresponde un caudal determinado dentro de una serie histórica. Por ejemplo, para clasificar un evento como percentil 90, identificar caudales de estiaje (percentiles bajos) o evaluar la posición relativa de un caudal observado.
La función de distribución empírica acumulada (ecdf, empirical cumulative distribution function) es la herramienta natural para esta tarea. Sin embargo, existen diferentes métodos para calcular percentiles, especialmente al invertir la función de distribución.
Este documento explora:
ecdf() en Rlibrary(tidyverse)
library(scales)
# Configuración de tema para gráficos
theme_set(theme_minimal(base_size = 11))Creamos una serie sintética de caudales diarios para un río, con características hidrológicas realistas:
set.seed(123)
# Serie de caudales (m³/s) con distribución log-normal
# Simulando un río con caudal medio de 15 m³/s
n_dias <- 1000
caudales <- tibble(
fecha = seq.Date(from = as.Date("2020-01-01"),
by = "day",
length.out = n_dias),
caudal = rlnorm(n_dias, meanlog = log(15), sdlog = 0.8)
) %>%
arrange(caudal)
# Resumen estadístico
summary(caudales$caudal) Min. 1st Qu. Median Mean 3rd Qu. Max.
1.584 9.074 15.111 20.890 25.527 200.514 La función ecdf() de R base crea una función escalonada que representa la probabilidad empírica acumulada:
# Crear la función ecdf
Fn <- ecdf(caudales$caudal)
# Ejemplos de uso: ¿Qué percentil corresponde a cada caudal?
caudales_prueba <- c(5, 10, 15, 20, 30, 50)
percentiles <- Fn(caudales_prueba) * 100
resultados_ecdf <- tibble(
caudal = caudales_prueba,
percentil = percentiles
)
print(resultados_ecdf)# A tibble: 6 × 2
caudal percentil
<dbl> <dbl>
1 5 8.3
2 10 29.2
3 15 49.5
4 20 64.2
5 30 81.1
6 50 92.7La función ecdf() es escalonada: aumenta en saltos discretos en cada valor observado de la muestra.
R ofrece 9 métodos diferentes para calcular percentiles (cuantiles) mediante la función quantile(). Los más relevantes son:
# Definir percentiles de interés
p_interes <- c(0.10, 0.25, 0.50, 0.75, 0.90, 0.95, 0.99)
# Calcular con diferentes métodos
metodos_comp <- map_dfr(1:9, function(tipo) {
tibble(
metodo = tipo,
percentil = p_interes * 100,
caudal = quantile(caudales$caudal, probs = p_interes, type = tipo)
)
})
# Comparación de métodos para percentiles clave
metodos_comp %>%
pivot_wider(names_from = metodo,
values_from = caudal,
names_prefix = "Tipo_") %>%
knitr::kable(digits = 2,
caption = "Caudales (m³/s) según método de cálculo")| percentil | Tipo_1 | Tipo_2 | Tipo_3 | Tipo_4 | Tipo_5 | Tipo_6 | Tipo_7 | Tipo_8 | Tipo_9 |
|---|---|---|---|---|---|---|---|---|---|
| 10 | 5.37 | 5.41 | 5.37 | 5.37 | 5.41 | 5.38 | 5.44 | 5.40 | 5.40 |
| 25 | 9.06 | 9.07 | 9.06 | 9.06 | 9.07 | 9.07 | 9.07 | 9.07 | 9.07 |
| 50 | 15.09 | 15.11 | 15.09 | 15.09 | 15.11 | 15.11 | 15.11 | 15.11 | 15.11 |
| 75 | 25.52 | 25.53 | 25.52 | 25.52 | 25.53 | 25.53 | 25.53 | 25.53 | 25.53 |
| 90 | 40.90 | 41.05 | 40.90 | 40.90 | 41.05 | 41.18 | 40.93 | 41.09 | 41.08 |
| 95 | 57.32 | 57.52 | 57.32 | 57.32 | 57.52 | 57.70 | 57.34 | 57.58 | 57.56 |
| 99 | 102.11 | 102.90 | 102.11 | 102.11 | 102.90 | 103.68 | 102.12 | 103.16 | 103.10 |
Para invertir la relación (dado un caudal Q, ¿qué percentil es?), necesitamos interpolar:
# Función para calcular percentil de un caudal dado
calcular_percentil <- function(Q, datos, metodo = 7) {
# Ordenar datos
x_ord <- sort(datos)
n <- length(x_ord)
# Si Q está fuera del rango
if (Q <= min(x_ord)) return(0)
if (Q >= max(x_ord)) return(100)
# Buscar posición mediante interpolación lineal de quantile()
# Usamos approx() para interpolar la función inversa
probs <- seq(0, 1, length.out = 100)
cuantiles <- quantile(x_ord, probs = probs, type = metodo)
percentil <- approx(x = cuantiles, y = probs * 100, xout = Q)$y
return(percentil)
}
# Aplicar a varios caudales de prueba
caudales_test <- seq(5, 60, by = 5)
resultados_inversion <- tibble(
caudal = caudales_test,
percentil_tipo4 = map_dbl(caudales_test,
~calcular_percentil(., caudales$caudal, metodo = 4)),
percentil_tipo7 = map_dbl(caudales_test,
~calcular_percentil(., caudales$caudal, metodo = 7)),
percentil_tipo8 = map_dbl(caudales_test,
~calcular_percentil(., caudales$caudal, metodo = 8))
)
print(resultados_inversion)# A tibble: 12 × 4
caudal percentil_tipo4 percentil_tipo7 percentil_tipo8
<dbl> <dbl> <dbl> <dbl>
1 5 8.53 8.42 8.48
2 10 29.3 29.2 29.2
3 15 49.6 49.5 49.6
4 20 64.4 64.4 64.4
5 25 74.0 74.0 73.9
6 30 80.9 80.9 80.9
7 35 86.0 86.0 86.0
8 40 89.3 89.3 89.2
9 45 91.3 91.3 91.3
10 50 92.8 92.8 92.8
11 55 94.0 94.0 93.9
12 60 95.3 95.3 95.3 # Preparar datos para gráfico
n_puntos <- length(caudales$caudal)
datos_plot <- tibble(
caudal = sort(caudales$caudal),
percentil_escalonado = (1:n_puntos) / n_puntos * 100
)
# Calcular versión interpolada (tipo 7)
percentiles_interp <- seq(0, 100, length.out = 500)
caudales_interp <- quantile(caudales$caudal,
probs = percentiles_interp/100,
type = 7)
datos_interpolados <- tibble(
caudal = caudales_interp,
percentil_interpolado = percentiles_interp
)
# Gráfico comparativo
ggplot() +
# Función escalonada (ecdf)
geom_step(data = datos_plot,
aes(x = caudal, y = percentil_escalonado,
color = "Escalonada (ecdf)"),
linewidth = 0.8) +
# Función interpolada
geom_line(data = datos_interpolados,
aes(x = caudal, y = percentil_interpolado,
color = "Interpolada (tipo 7)"),
linewidth = 0.8) +
# Líneas de referencia para percentiles clave
geom_hline(yintercept = c(10, 50, 90),
linetype = "dashed",
alpha = 0.3) +
scale_color_manual(values = c("Escalonada (ecdf)" = "#2C3E50",
"Interpolada (tipo 7)" = "#E74C3C")) +
scale_x_continuous(labels = comma) +
labs(
title = "Comparación: Función de distribución escalonada vs interpolada",
subtitle = "Serie de caudales diarios (n = 1000)",
x = "Caudal (m³/s)",
y = "Percentil (%)",
color = "Método"
) +
theme(legend.position = "bottom")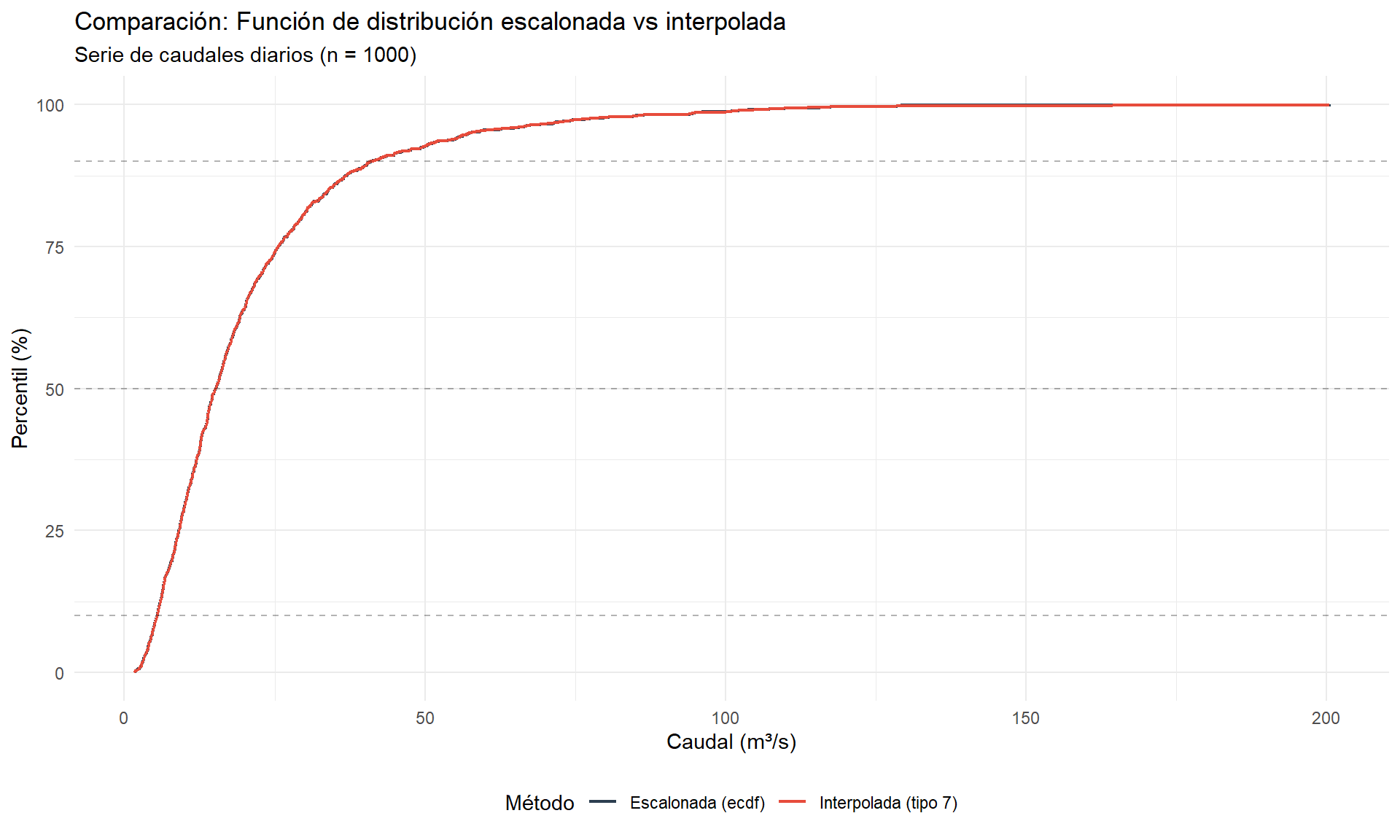
# Zoom en percentiles bajos (estiaje)
p1 <- ggplot() +
geom_step(data = datos_plot %>% filter(percentil_escalonado <= 20),
aes(x = caudal, y = percentil_escalonado),
color = "#2C3E50", linewidth = 1) +
geom_line(data = datos_interpolados %>% filter(percentil_interpolado <= 20),
aes(x = caudal, y = percentil_interpolado),
color = "#E74C3C", linewidth = 1, linetype = "dashed") +
labs(title = "Percentiles bajos (estiaje)",
x = "Caudal (m³/s)",
y = "Percentil (%)") +
theme_minimal()
# Zoom en percentiles altos (avenidas)
p2 <- ggplot() +
geom_step(data = datos_plot %>% filter(percentil_escalonado >= 80),
aes(x = caudal, y = percentil_escalonado),
color = "#2C3E50", linewidth = 1) +
geom_line(data = datos_interpolados %>% filter(percentil_interpolado >= 80),
aes(x = caudal, y = percentil_interpolado),
color = "#E74C3C", linewidth = 1, linetype = "dashed") +
labs(title = "Percentiles altos (crecidas)",
x = "Caudal (m³/s)",
y = "Percentil (%)") +
theme_minimal()
# Combinar gráficos
library(patchwork)
p1 + p2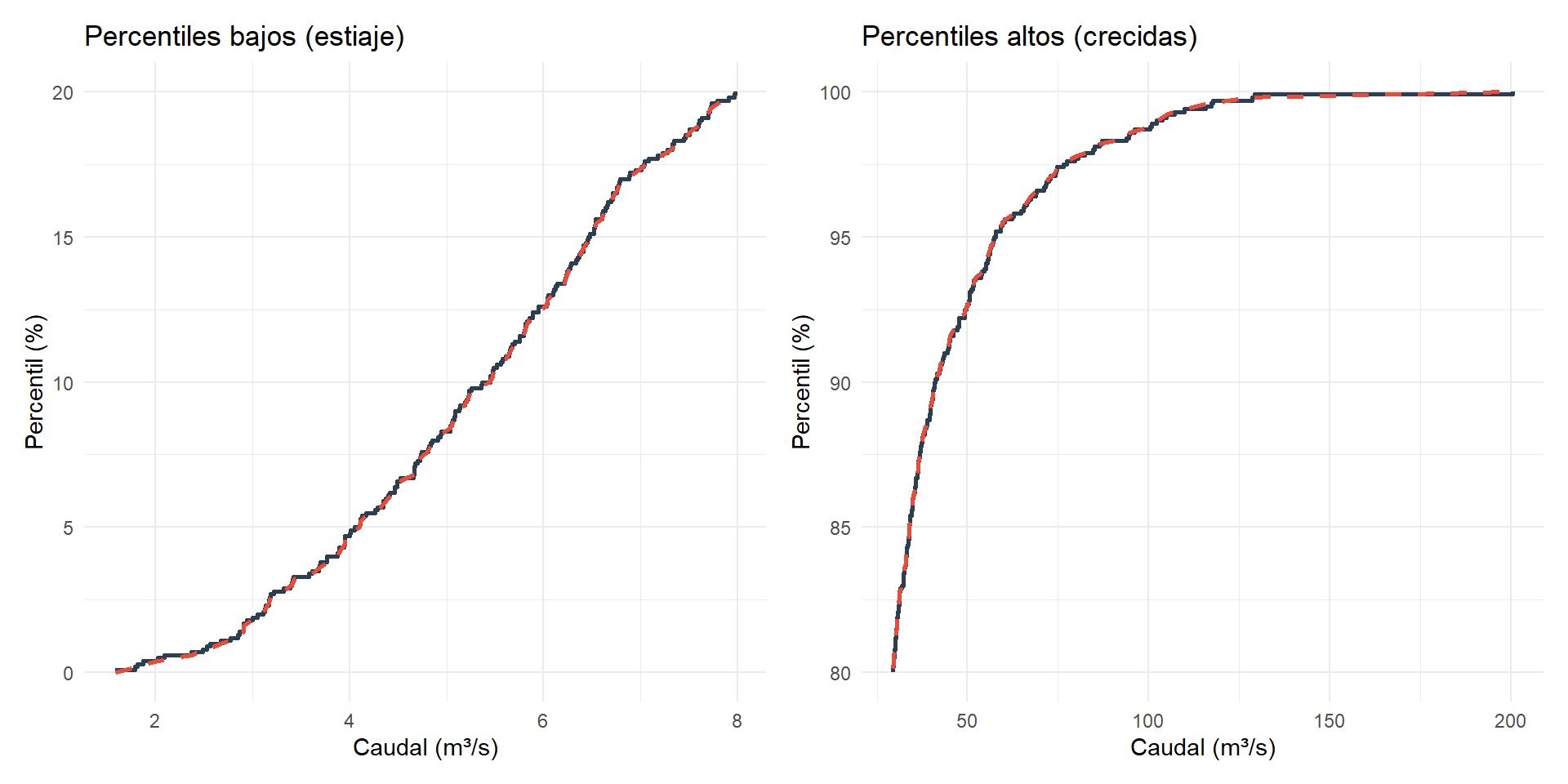
Clasificamos los caudales según su percentil:
# Función para clasificar caudal según percentil
clasificar_caudal <- function(Q, datos) {
percentil <- calcular_percentil(Q, datos, metodo = 7)
categoria <- case_when(
percentil < 10 ~ "Estiaje extremo",
percentil < 25 ~ "Estiaje",
percentil < 75 ~ "Normal",
percentil < 90 ~ "Crecida",
percentil < 95 ~ "Crecida importante",
TRUE ~ "Avenida excepcional"
)
return(list(percentil = percentil, categoria = categoria))
}
# Ejemplos de clasificación
caudales_ejemplo <- c(3, 8, 15, 25, 40, 60)
clasificaciones <- map_dfr(caudales_ejemplo, function(Q) {
resultado <- clasificar_caudal(Q, caudales$caudal)
tibble(
caudal = Q,
percentil = round(resultado$percentil, 1),
categoria = resultado$categoria
)
})
print(clasificaciones)# A tibble: 6 × 3
caudal percentil categoria
<dbl> <dbl> <chr>
1 3 1.8 Estiaje extremo
2 8 20.2 Estiaje
3 15 49.5 Normal
4 25 74 Normal
5 40 89.3 Crecida
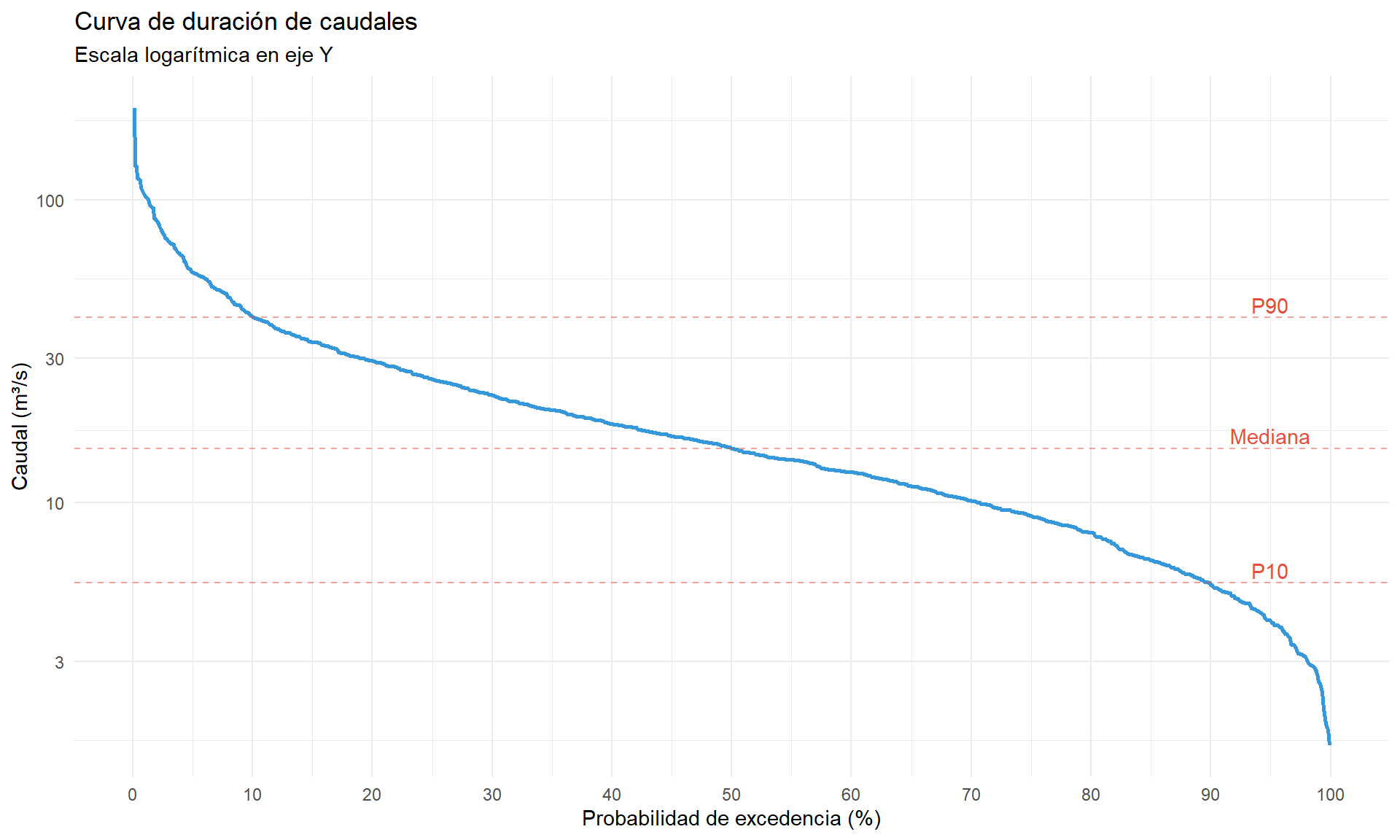
6 60 95.3 Avenida excepcionalUna aplicación clásica de la ecdf en hidrología:
# Curva de duración (ordenar de mayor a menor)
caudales_duracion <- caudales %>%
arrange(desc(caudal)) %>%
mutate(
orden = row_number(),
prob_excedencia = (orden) / (n() + 1) * 100
)
ggplot(caudales_duracion, aes(x = prob_excedencia, y = caudal)) +
geom_line(color = "#3498DB", linewidth = 1) +
geom_hline(yintercept = quantile(caudales$caudal, c(0.10, 0.50, 0.90)),
linetype = "dashed", alpha = 0.5, color = "#E74C3C") +
annotate("text", x = 95, y = quantile(caudales$caudal, 0.90) * 1.1,
label = "P90", color = "#E74C3C") +
annotate("text", x = 95, y = quantile(caudales$caudal, 0.50) * 1.1,
label = "Mediana", color = "#E74C3C") +
annotate("text", x = 95, y = quantile(caudales$caudal, 0.10) * 1.1,
label = "P10", color = "#E74C3C") +
scale_x_continuous(breaks = seq(0, 100, 10)) +
scale_y_log10(labels = comma) +
labs(
title = "Curva de duración de caudales",
subtitle = "Escala logarítmica en eje Y",
x = "Probabilidad de excedencia (%)",
y = "Caudal (m³/s)"
)
La función ecdf() proporciona la función de distribución empírica acumulada, que es escalonada por naturaleza.
Para invertir la relación (de caudal a percentil), es recomendable usar métodos interpolados, especialmente el tipo 7 (por defecto en R) o el tipo 8 (aproximadamente insesgado).
La diferencia entre métodos es más notable en los extremos de la distribución y en muestras pequeñas.
En hidrología práctica, para series largas (n > 100), las diferencias entre métodos son generalmente menores que las incertidumbres de medición.
Aplicaciones principales: